June 14, 2025
Compute as People
How many human worker equivalents can we get from current compute?
TLDR: Even if LLMs could do every white-collar task tomorrow, we only have enough GPUs to replace ~1 % of the world’s knowledge workforce.
The METR Time Horizons study had humans and AI models compete on the same software engineering tasks. We’ve mostly been interested in this work for what it says about AI capabilities, especially with respect to reliability on long tasks. But this also lets us crudely denominate our compute in terms of equivalent human workers.
From tokens to labor hours. Among tasks that models could complete reliably, they could do so for less than 10% of the cost of a software engineer.1 In another paper focusing on RE-Bench, the authors draw an equivalence between a cost in human labor to a number of input/output tokens.2 Plugging this into a simple back-of-the-envelope, along with current API prices and H100 runtime costs, you can estimate that about 0.5 hours of H100 runtime is equivalent to 1 hour of expert human labor - on the subset of tasks current models already solve.3
Current compute supply. Epoch AI estimates that NVIDIA’s installed compute as of the end of 2024 was about 4 million H100 equivalents. NVIDIA has roughly 90% GPU market share, so I’m going to treat this as total global compute for running AI models. That means that even if 100% of compute were invested in inference, it could only in theory provide the labor of 8,000,000 human work hours per hour. By contrast, our global workforce of human knowledge workers is roughly 1 billion.
AI is small. This comparison illustrates the extent to which we’re still compute constrained. We might ask ourselves “if AI is really so capable, why isn’t it having a bigger economic impact now?” Yet, even if AI were capable of doing 100% of knowledge work, our global compute supply would only allow us to increase our effective knowledge work force on the order of 1% (8 million AI worker equivalents vs. 1 billion human workers).
Compute trends. But the amount of effective compute is changing fast, even relative to other trends in AI. Part of this is because the amount of raw GPU capacity is doubling each year (again see Epoch AI), but far more dramatic is the precipitous decline in inference costs. In less than two years, the cost per million tokens of GPT-4-style inference fell from roughly $40 to $0.10.
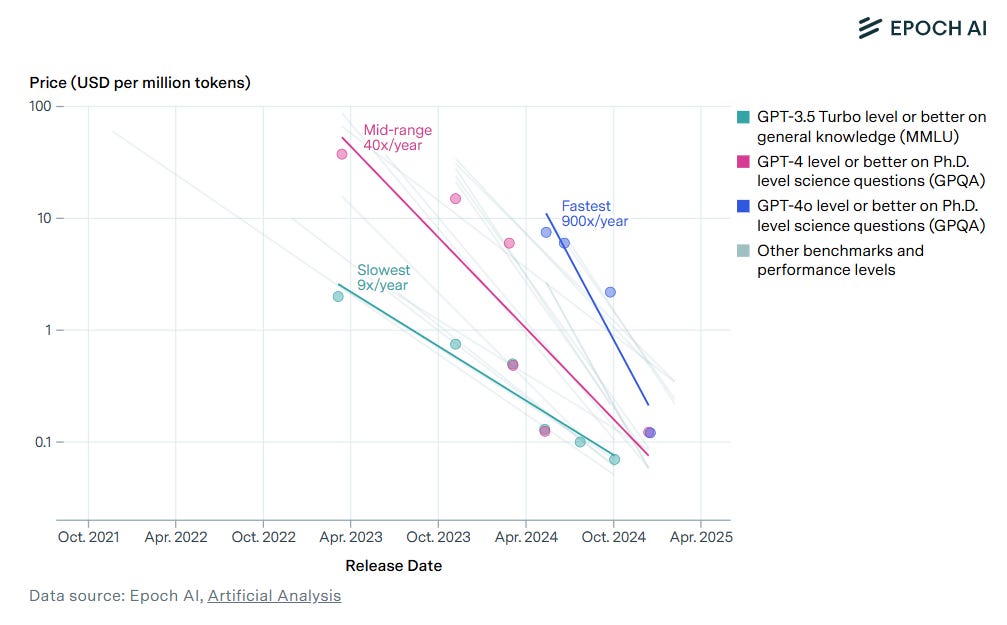
Outlook for 2027. The effective population of geniuses within the data center increases proportionally with declines in the cost of inference compute. If the cost of inference continues to fall by at least one order of magnitude per year, we’ll go from having enough compute to automate roughly 1% of knowledge workers in 2025, to 10% in 2026, to 100% in 2027. If inference costs continue to fall, the 2025 situation and 2027 situation look very different.